

This article is a continuation of my previous article, "Bit hacks in C#." decided to drop the C# bit since most of the time, 99% of the examples presented there were almost one to one used in other languages.
Last time we were looking at some simple bit hacks and how to construct more complex out of the basic ones. There was a bonus section that briefly described a very (In)famous function called "hasZeroByte."
I told you before that the bonus section is full of dragons, this article is full of dragons and they are flying upside down :)
This function is vital for a couple of reasons:
- It allows us to implement range functions on bytes.
- We can use those functions to build branch-free string operations.
Let's look at the function again and understand what it does in more depth:
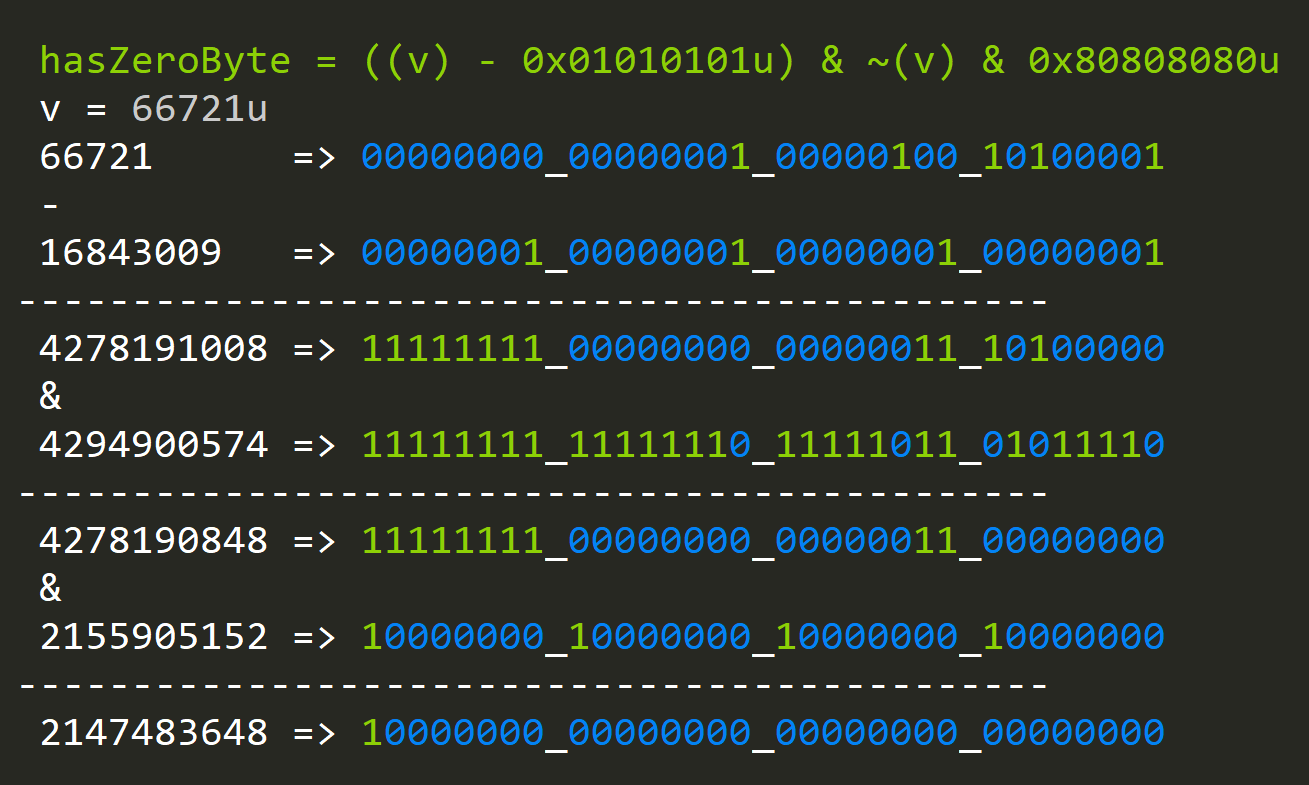
hasZeroByte = ((v) - 0x01010101u) & ~(v) & 0x80808080u
"hasZeroByte" looks scary when we look at it, but when we try to understand the logic behind it, it turns out to be not so frightening.
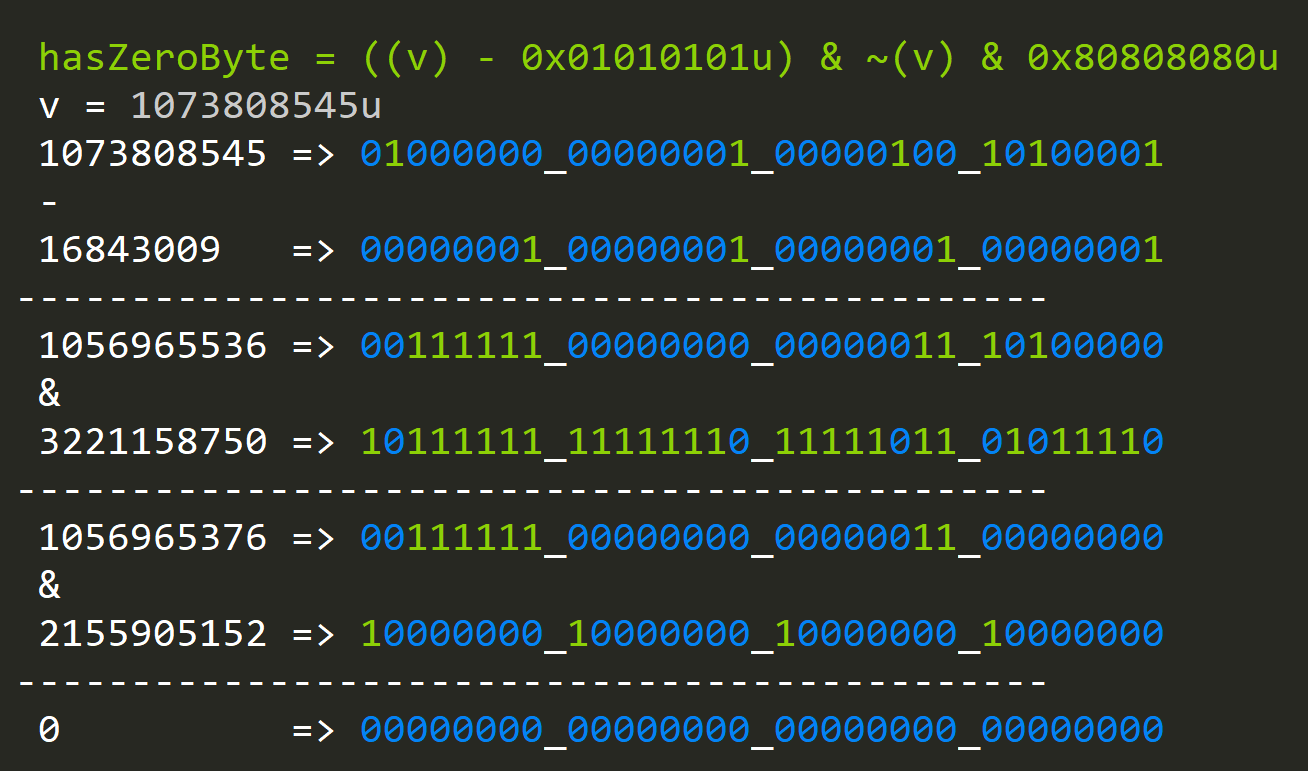
TLDR: This function checks if the value is in at least one of two ranges. If it isn't, then we conclude that our value has a byte that's zero; otherwise, we don't have a zero byte.
When the value has a zero byte:
When the value doesn't have a zero byte:
Let's go step by step:
- (v) - 0x01010101u: This subexpression will set the most significant bit of a byte if it's over 128.
- ~(v) this unary subexpression will flip the most significant bit of a byte if the byte value is below 128.
- The only value that is not present in both of these sets is 0 so when we do: ((v) - 0x01010101u) & ~(v) only a value that's not part of any range will have its significant bit set.
- The last AND 80808080u will do and with the most significant bit of every byte and that's true *only* for zero bytes.
And voila, we have our solution to the zero-byte problem.
Now we can use this function to look for something else than zero; we can pick any value:
hasByteValue = hasZeroByte((x) ^ (~(0u) / 255 * (n))))
Let's look closely at the subexpression: ~0u / 255:
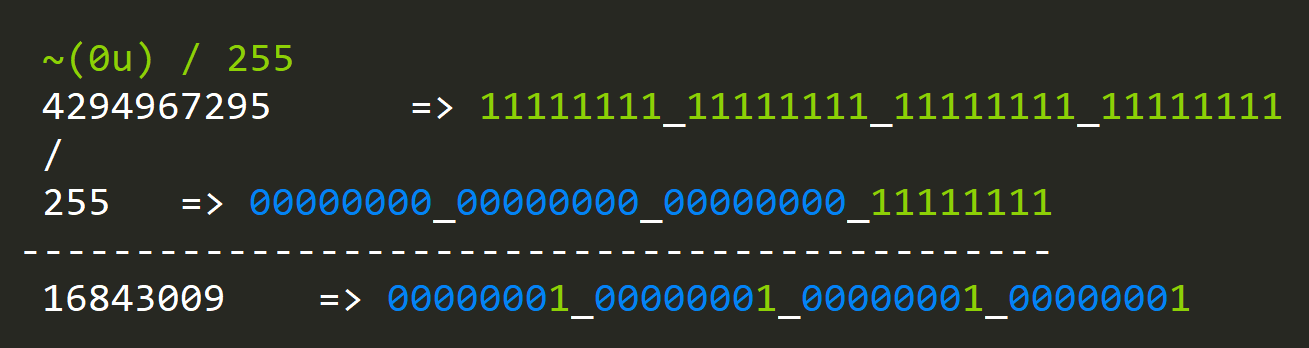
This looks like one of the magic constants from "hasZeroByte":

Indeed the result is identical; this means that by substracting such sequence, we effectively eliminate the first range check, and from now on, we're free to look for values in bytes from 0 to 128.
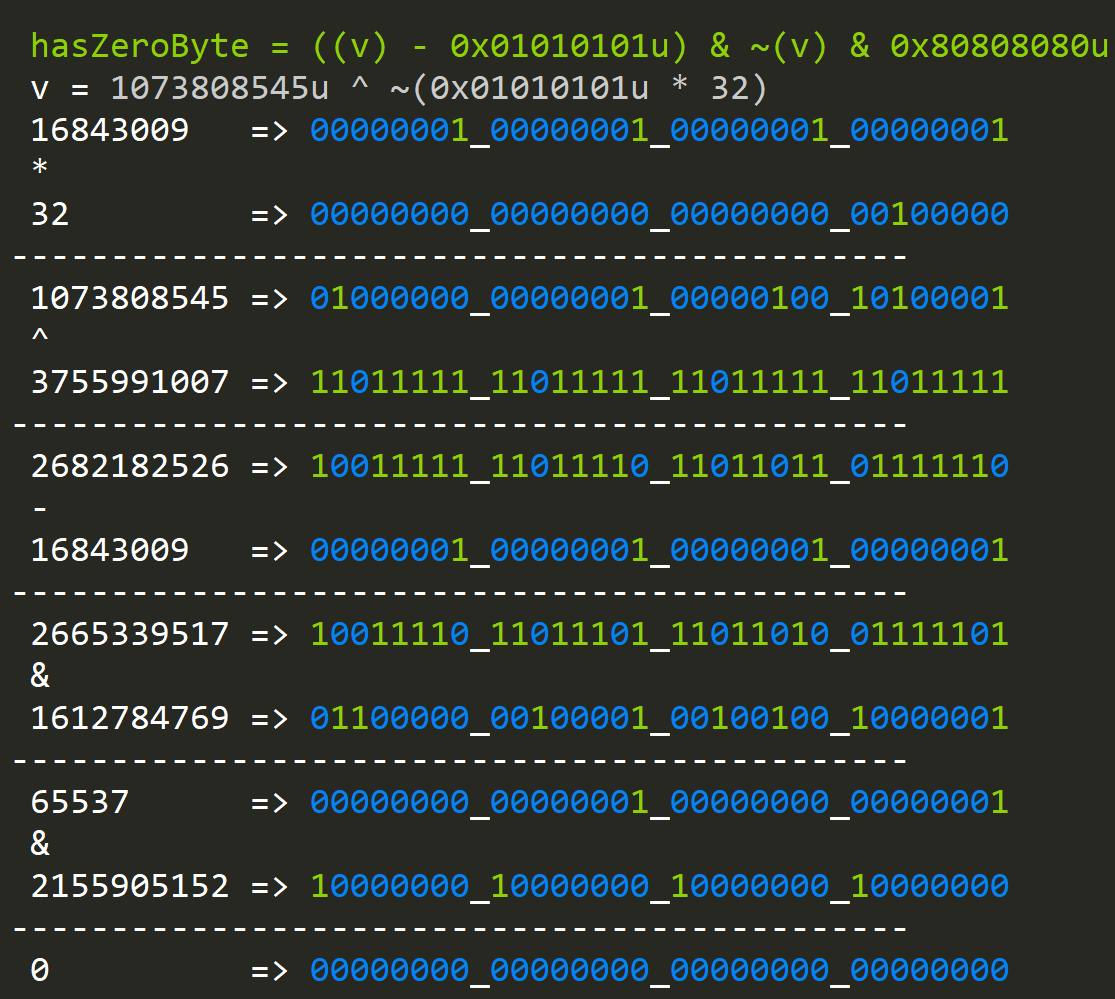
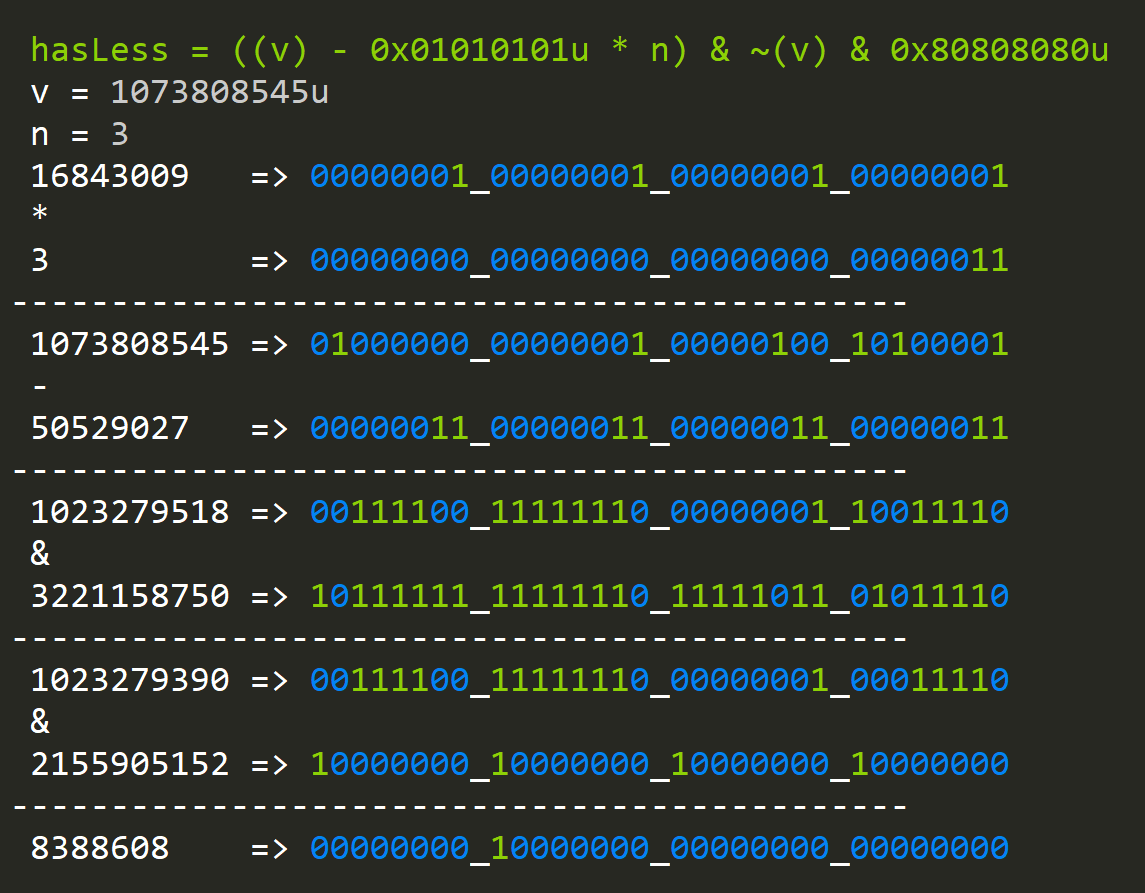
Let's further build on this idea and construct a function that will allow us to find a byte that's less than a given value "n":
hasLess = (x - ~(0u)/255*n) & ~(x) & ~(0u)/255*128
Can you see it? It's the zero byte function with added variables:
- ~0u / 255 is 0x01010101u
- ~0u /255*128 is 80808080u
So if we want something less then "n" we increase, the first range by n.
In this example we are looking for values less then one and our number doesn't have any:
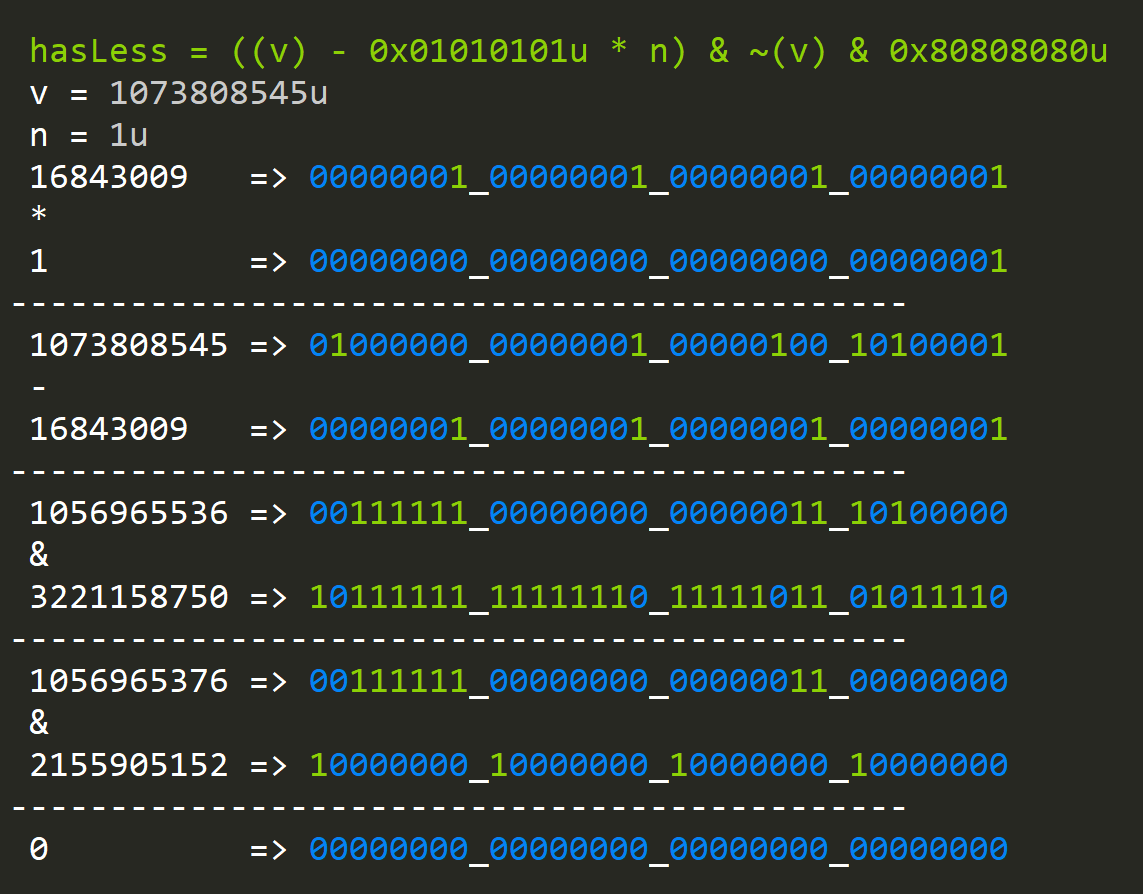
When we have values less than "n":
Knowing all this, how would we create a function that finds bytes greater than "n"?
hasMore = (x + ~(0U)/255u * (127 - n) | x) & ~(0U)/255 * 128
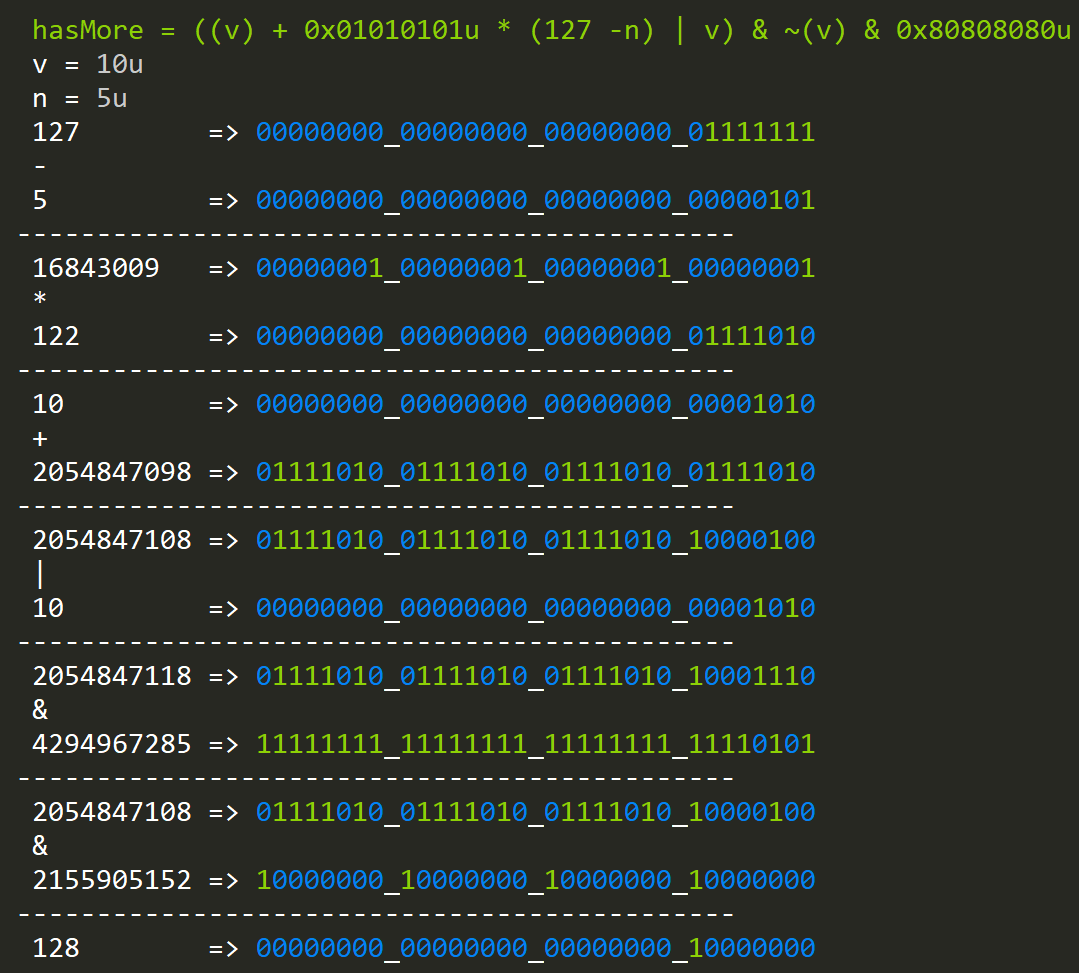
The first subexpression will set the high bits to all the bytes that are grater then n and are from 1 to 129. To fix this problem, we AND with the value itself to set the high bits. Lastly, we AND with a value that has all high bits set in each byte.
So I told you that this collection of bit hacks is used to do efficient string processing, and it's not hard to imagine how. UTF-16 characters are from 2 to 4 bytes long, and if we want to check if a string contains say; a new line '\n,' how many are there and where they are, we could use the "hasByteValue" function.
public static int CountNewLineWORD(string text)
{
int count = 0;
byte charToFind = (byte)'\n';
unsafe
{
fixed (char* ch = text)
{
int len = text.Length;
int i = 0;
int lastBlockIndex = len - (len % 4);
while (i < lastBlockIndex)
{
ulong* p = (ulong*)(ch + i);
var result = HasValue(*p, charToFind);
if (result > 0)
{
if (*(ch + i + 0) == charToFind) count++;
if (*(ch + i + 1) == charToFind) count++;
if (*(ch + i + 2) == charToFind) count++;
if (*(ch + i + 3) == charToFind) count++;
}
i += 4;
}
while (i < len)
{
char* c = (char*)(ch + i);
if (*c == charToFind)
{
count++;
}
i += 1;
}
return count;
}
}
}
(For code simplicity this code only counts the instances of newline chars, but it's trivial to extend the code)
Instead of reading a single character at the time, we read a full x64 word (64bits). Reading x64 WORDs allows us to skip a large number of characters if they don't contain the new line.
When we do encounter a new line, the simplest thing to do is to process each character and record the found position.
Lastly, if the characters cannot fit into 8 bytes unsigned long value, we switch to checking every character, but that's fine since there's less of them than four.
Let's compare results with a simple function that checks each character:
public static int CountNewLine(string text)
{
int count = 0;
foreach(var c in text)
{
if (c == '\n')
count++;
}
return count;
}
That's not a bad improvement.
How are the tests performed?
Since we want to avoid branch prediction and branch learning by the CPU in each test iteration, we generate a new string using a random function with semi-random seed. Such a carefully constructed test allows us to measure the timings of code with branches correctly; otherwise, each iteration would be faster than the last one.
Additionally, we are randomizing places where we can find new lines.
public void IterationSetup()
{
text = GenerateRandomTest();
}
private string GenerateRandomTest()
{
var words = sample.Split(' ');
int newLine = 0;
int newLineEvery = 100;
StringBuilder builder = new StringBuilder();
Random rnd = new Random(DateTime.Now.Millisecond);
for (int i = 0; i < len; i++)
{
newLine += rnd.Next(1, 10);
if (newLine >= newLineEvery)
{
builder.Append('\n');
newLine = 0;
}
builder.Append(words[rnd.Next(0, words.Length)]);
}
return builder.ToString();
}Can we do better?
Bit Count (PopCount):
Yes, if we look closely at the "hasZeroByte" and "hasValue" functions, we could see that the last subexpression ( & 80808080u ) is only going to produce values other then zero if the final result also has its high bits set. So we could use this count on how many bytes had a specific byte or value set.
To be able to do this, we need a function that can count bits in an integer:
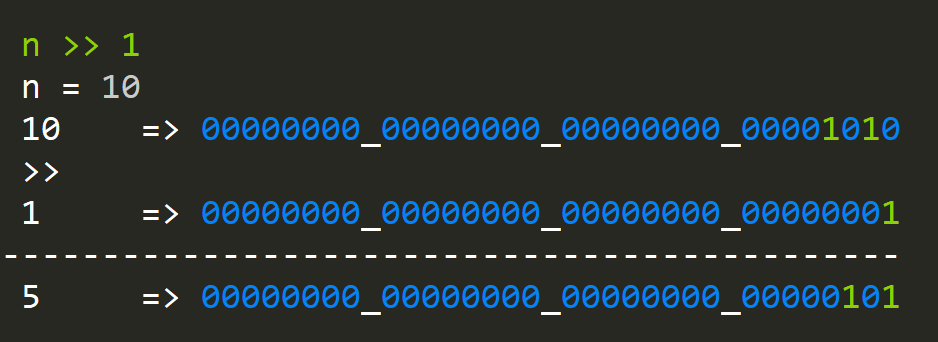
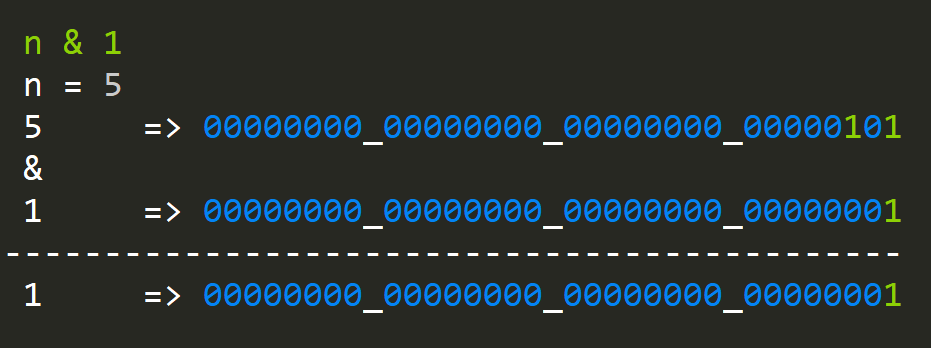
public static int BitCount(int n)
{
int counter = 0;
while (n > 0)
{
counter += n % 1;
n >>= 1;
}
return counter;
}We iterate through the number shifting it to the right effectively pushing all the ones to the least significant bit and AND(ing) with one:
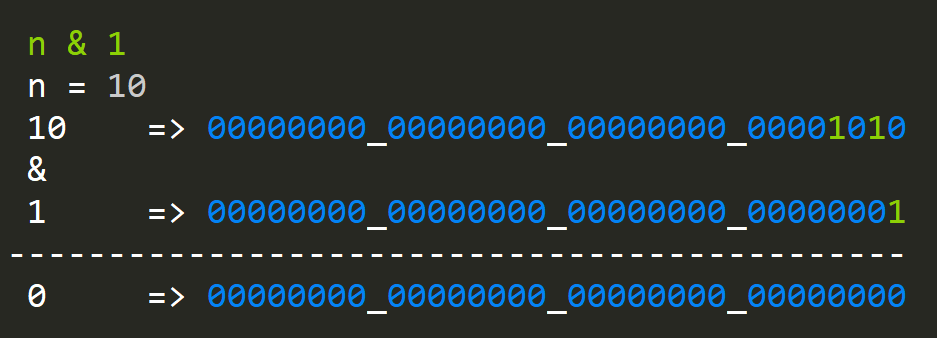
How does it perform?

Not bad, but the branching version wins. We can do better.
Our function is iterative. That's not very effective, so we could use our current knowledge and create an expression that doesn't have iterations by creating masks that we can use to do partial sums.
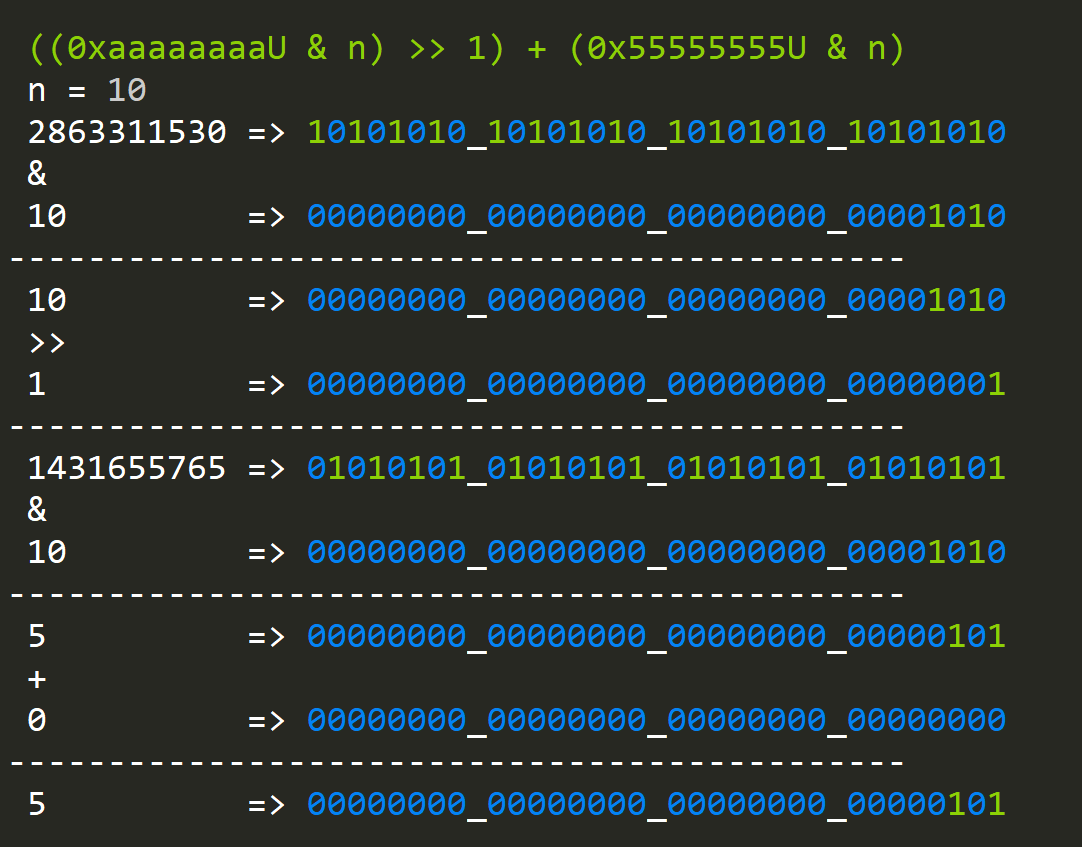
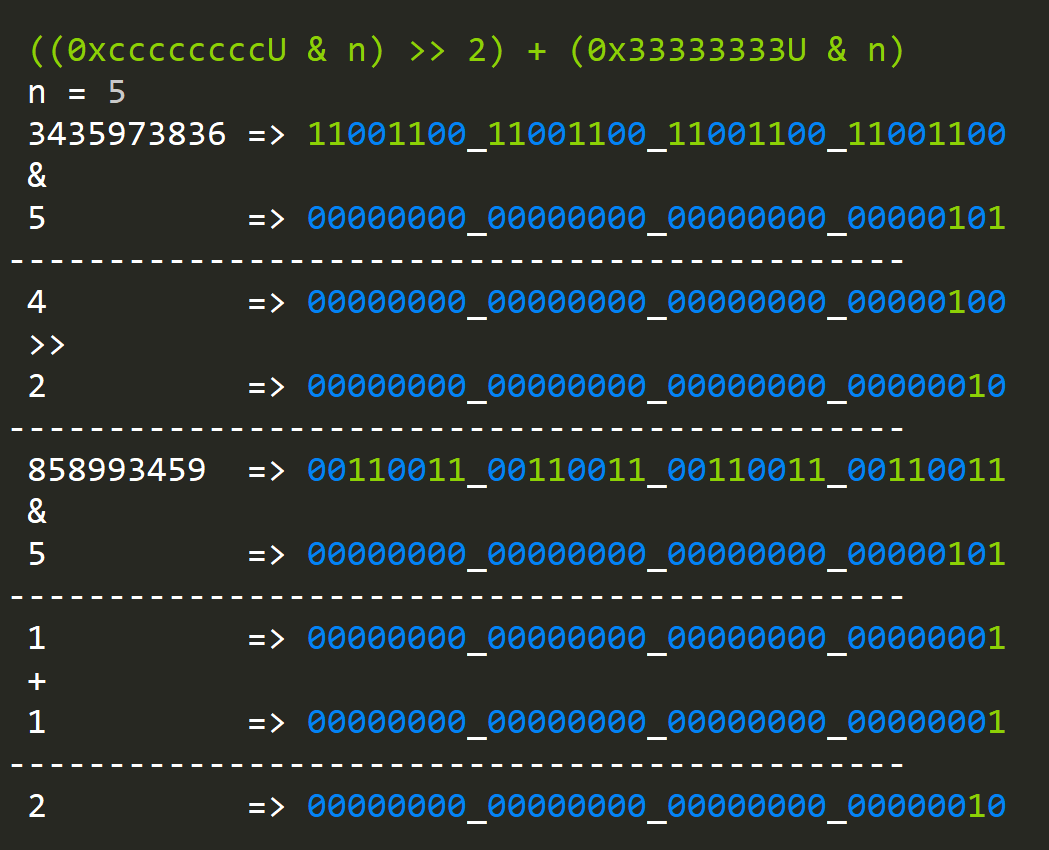
public static uint BitCount(uint n)
{
n = ((0xaaaaaaaaU & n) >> 1) + (0x55555555U & n);
n = ((0xccccccccU & n) >> 2) + (0x33333333U & n);
n = ((0xf0f0f0f0U & n) >> 4) + (0x0f0f0f0fU & n);
n = ((0xff00ff00U & n) >> 8) + (0x00ff00ffU & n);
n = ((0xffff0000U & n) >> 16) + (0x0000ffffU & n);
return n;
}- The first expression sums 16 different 1-bit values.
- The second expression will sum 8 different, 2-bit values.
- The third expression will sum 4 different 4-bit values.
- You get the idea...
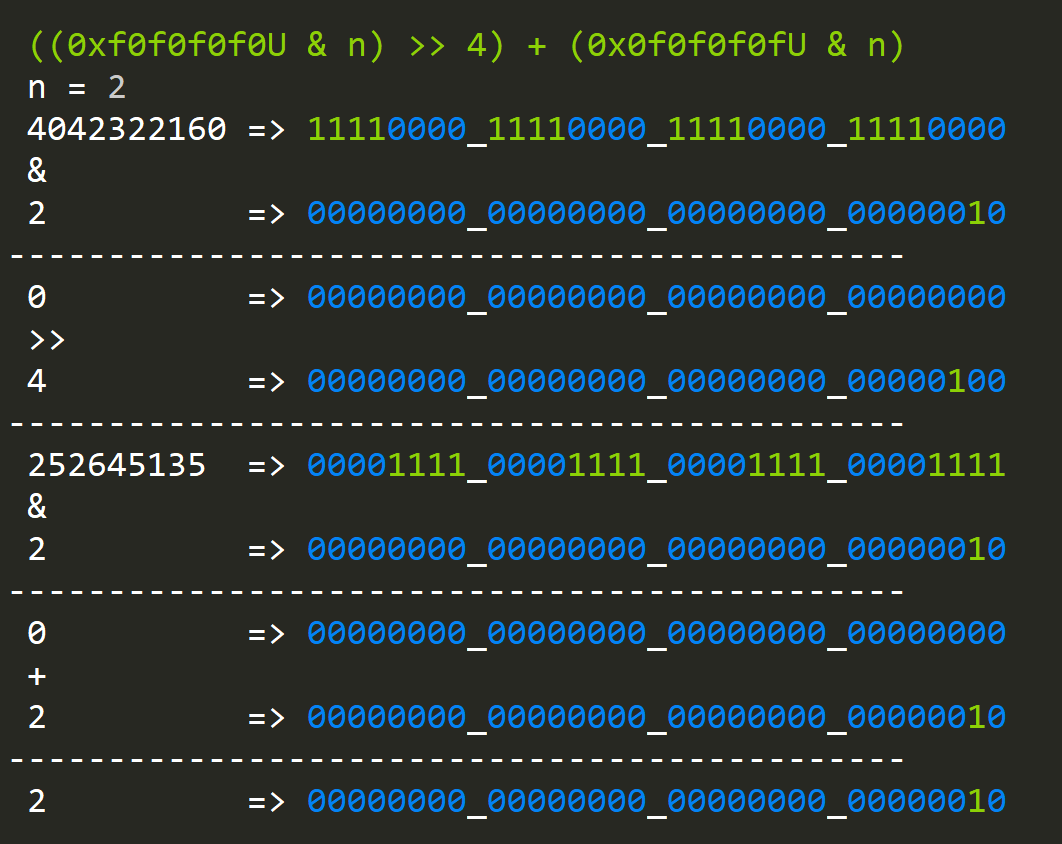
This is a clever function, but it's not very efficient since it still has a lot of operations that need computation, so the performance is going to be similar to iterative bit count:

Let's try a more optimized version that takes the same idea but does so in a smaller number of operations:
public static ulong BitCountSWAR(ulong x)
{
x -= (x >> 1) & 0x5555555555555555UL;
x = (x & 0x3333333333333333UL) + ((x >> 2) & 0x3333333333333333UL);
x = (x + (x >> 4)) & 0x0f0f0f0f0f0f0f0fUL;
//returns left 8 bits of x + (x<<8) + (x<<16) + (x<<24) + ...
return (x * 0x0101010101010101UL) >> 56;
}This algorithm and the previous one belongs to a family called SWAR (SIMD Within A Register) that uses bit hacks to achieve instruction parallelism. Thus they can be vectorized (because we're effectively doing multiple counts that we store in two accumulators).
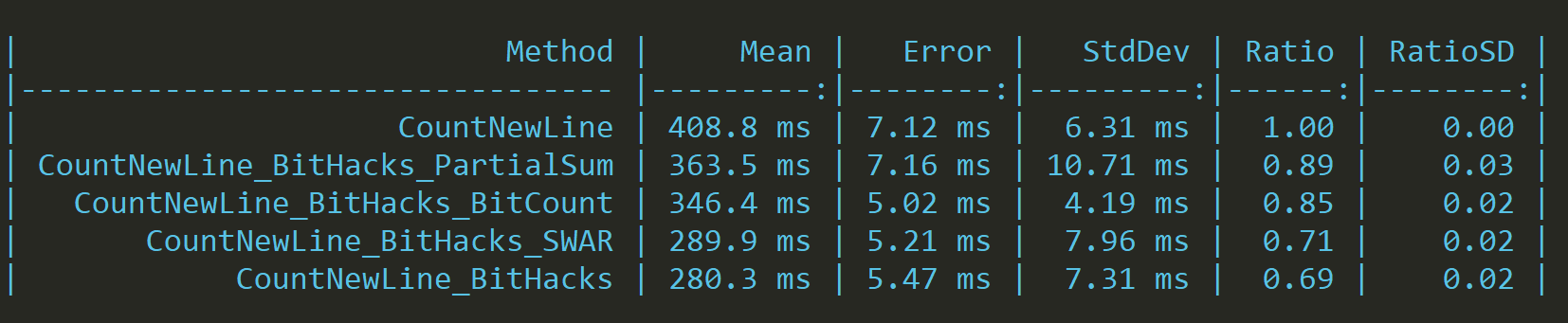
Now the results are comparable with the version that we started with, and why is that?
On average, the SWAR version will outperform the simple branch solution, and (even hardware-based bit counting solutions):

The bit manipulation algorithms work best where we have a dense population, meaning that there are lots of ones in the WORD. It's not the case here, and to make matters worse, we're doing meaningless work on 4 bytes since we know that newlines are stored in the first byte of the character type. That's why the current state of the art bit count is just slightly faster than a simple equality check when faced with this problem.
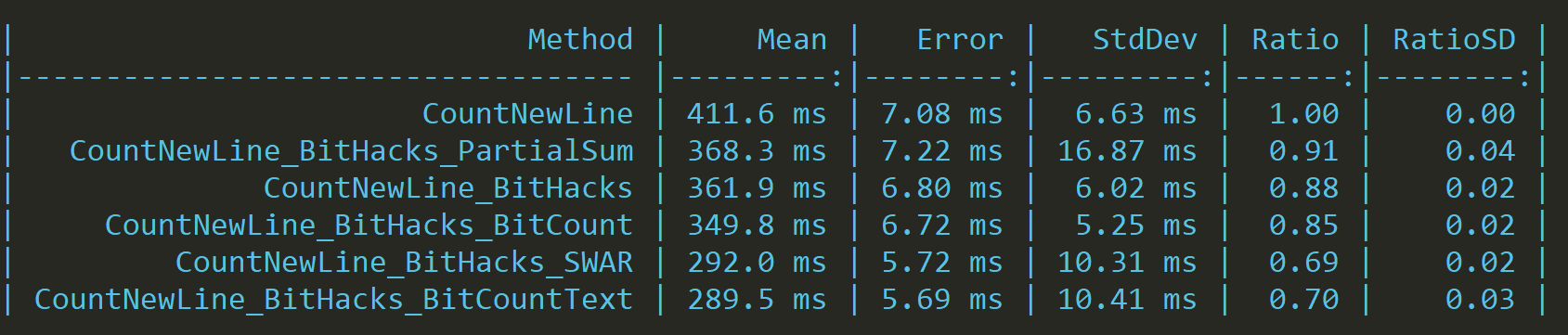
But since we know that the "hasByteValue" function will set the most significant bits of each byte and we should count only odd bytes. We can modify each bit hacking function to incorporate this information and effectively cut the number of operations by half.
Let's try it for the simple bit count:
public static ulong BitCountText(ulong n)
{
ulong counter = 0;
counter += (n >> 7) & 1;
counter += (n >> 23) & 1;
counter += (n >> 39) & 1;
counter += (n >> 55) & 1;
return counter;
}
There's still one solution that we shall use; there's a hardware function that can count bits for us called PopCount.
Popcnt.X64.PopCount
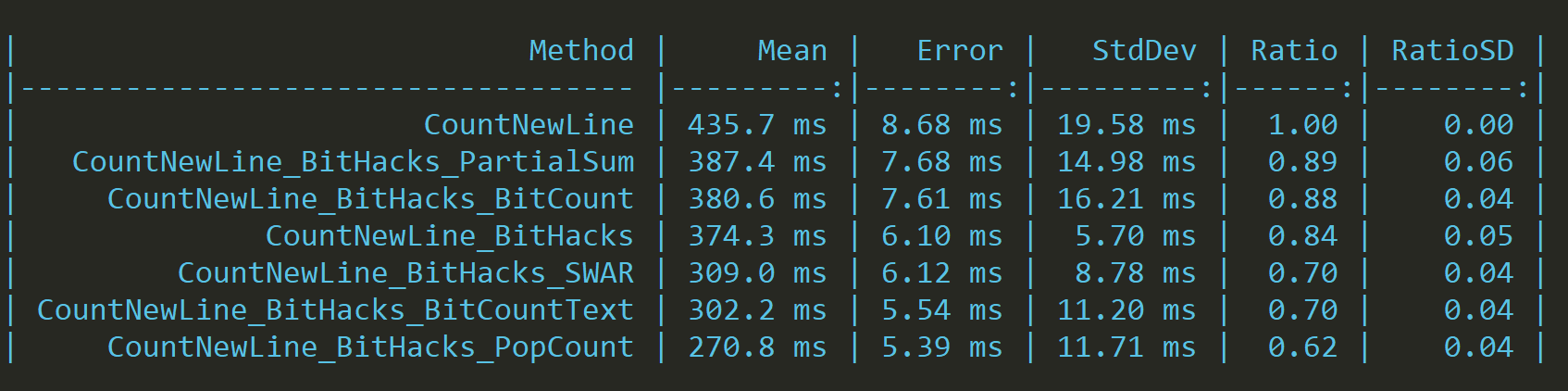
It's hard to be faster than a hardware instruction; however, on some processors, this instruction contains a bug. It introduces fake instruction dependency, and as a result, it's slower then it should be, and SWAR bit counting could be faster.
All of the bit hacks thus far can be vectorized to be much more efficient, but since we're spending most of our time in "hasByteValue" let's convert it to SIMD.
public static unsafe uint CountNewLineSIMD(string text)
{
uint counter = 0;
int len = text.Length;
fixed (char* c = text)
{
Vector128<ulong> highBits = Vector128.Create(0x8080808080808080UL);
Vector128<ulong> lowBits = Vector128.Create(0x0101010101010101UL);
Vector128<ulong> needle =
Vector128.Create(0x0101010101010101UL * (uint)'\n');
int i = 0;
int lastBlockIndex = len - (len % 8);
while (i < lastBlockIndex)
{
ulong* p = (ulong*)(c + i);
var vec = Sse2.LoadVector128(p);
var result = Sse2.Xor(vec, needle);
var expr1 = Sse2.Subtract(result, lowBits);
var expr2 = Sse2.AndNot(result, highBits);
var expr3 = Sse2.And(expr1, expr2);
var mask = (uint)Sse2.MoveMask(expr3.AsByte());
counter += Popcnt.PopCount(mask);
i += 8;
}
while (i < len)
{
if (text[i] == '\n')
counter++;
i += 1;
}
}
return counter;
}This code recreates the expressions:
hasZeroByte = ((v) - 0x01010101u) & ~(v) & 0x80808080u
and
hasByteValue = hasZeroByte((x) ^ (~(0u) / 255 * (n))))
It quickly uses the hardware instruction popcount to count newlines in a WORD. We could also implement a Vectorized BitCount that could (and probably would) outperform the hardware instruction since it will work on 128/256 bit vectors.
For example, this paper outlines how to do it.
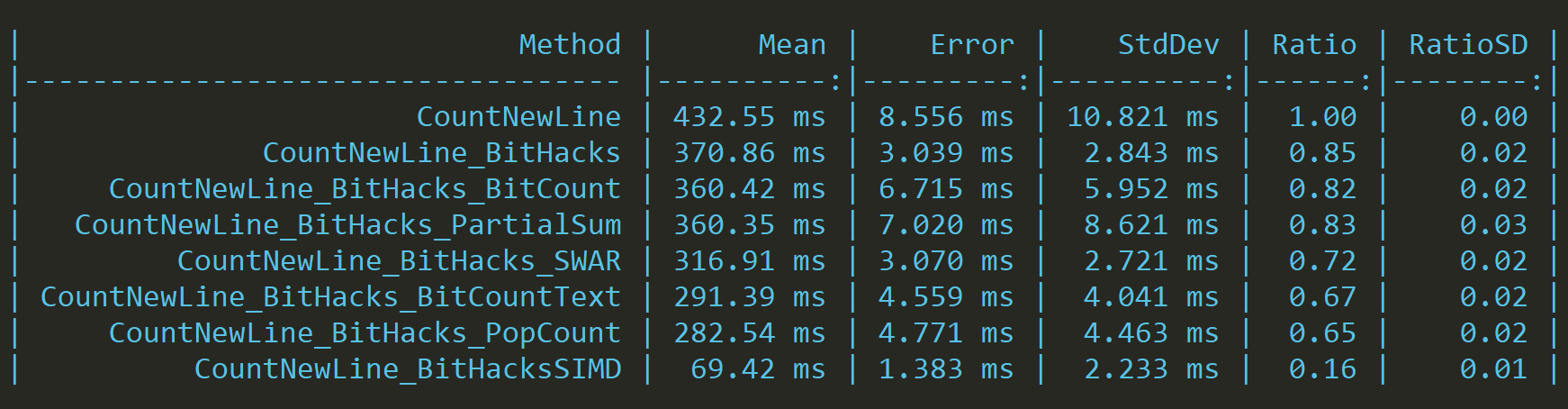
Now we're fast (4-5x times), but we can still do better. Without implementing a very complicated vectorized popcount function. As it turns out, SIMD instructions have a build-in Equals intrinsic, and it's pretty fast.
public static unsafe uint CountNewLineSIMDEquals(string text)
{
uint counter = 0;
int len = text.Length;
fixed (char* c = text)
{
Vector128<byte> vresult = Vector128<byte>.Zero;
Vector128<byte> newLine = Vector128.Create((byte)'\n');
int i = 0;
int lastBlockIndex = len - (len % 8);
while (i < lastBlockIndex)
{
byte* p = (byte*)(c + i);
var vec = Sse2.LoadVector128(p);
var result = Sse2.CompareEqual(vec, newLine);
var mask = (uint)Sse2.MoveMask(result);
counter += Popcnt.PopCount(mask);
i += 8;
}
while (i < len)
{
if (text[i] == '\n')
counter++;
i += 1;
}
}
return counter;
}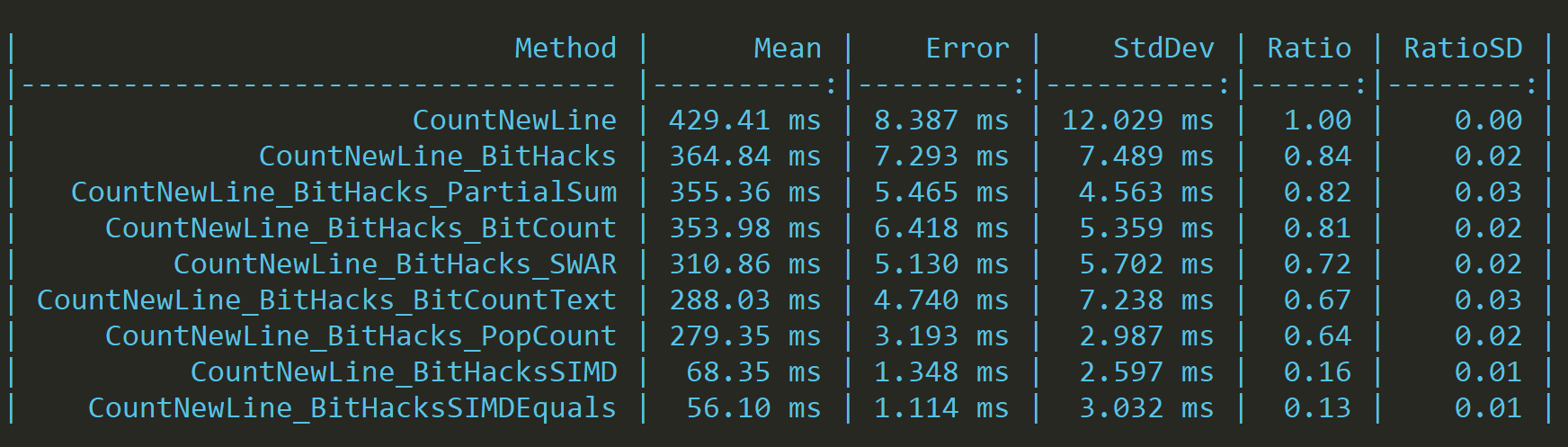
The performance seems a bit better, but having done multiple tests on varying data sets has led me to conclude that they are identical.
We can still do better, but at this point, we have to construct expressions specifically for our problem or implement vectorized bit count or both. Since this article is getting long, we shall probably look at some in the next article.
Summary:
We started from a simple idea, and we were building on it until we reached a 2x performance gain without doing any SIMD, With Intrinsics, we can go 4-5x times faster, and I have made no effort to optimize the SIMD code (we can improve it even further with instruction-level parallelism).
This content took a while to create, so if you like it, please consider buying me a coffee 😉

